






These global innovators grew with us

Jennifer Dunn
Director of Operations and Innovation
Woligo
“As an implementation partner, Neutrinos truly understood our core business. I appreciate the flexibility Neutrinos’ low code development solution provided... and the team was one of the best I have worked with.”

Santosh Gon
CIO
Aviva Sing Life Insurance, Singapore
“Your teams could develop a prototype in 2-3 weeks, and I think that’s quite phenomenal. I have seen through the last many years implementing new digital strategies but being able to deliver something into 2-3 weeks where you are able to translate client’s vision or dreams into something which is more visual is outstanding and its very unique of Neutrinos – Great Job and Keep Up the Good Work!”
You can too.
With a partner that helps you

Turn your Digital Dreams
into Reality
with unique design thinking and technology building blocks.
Dream Big and Transform
Business Incrementally
with de-risked and trusted approaches.
Revitalize ROI and Boost
Customer Retention
with Neutrinos Infinity Composer.
Achieve Limitless Potential
with a Global Ecosystem
of top-tier vendors and transformation programs.
Just like these inspiring stories did
At Neutrinos, we empower your success by bringing your digital aspirations to life and championing a culture of prosperity that delivers business value across categories.
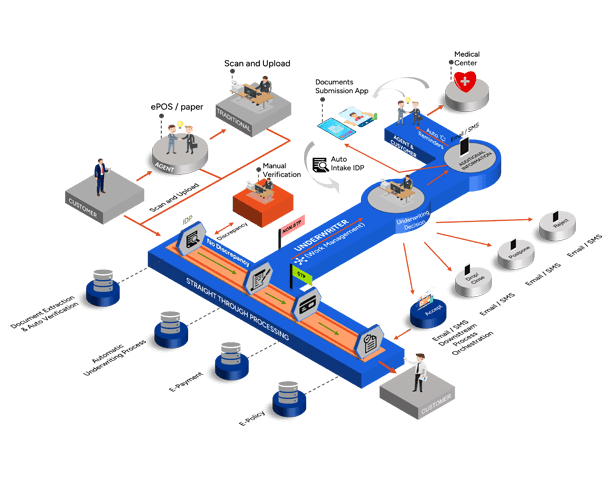
Making underwriting fast, accurate and transparent
Reimagined Underwriting Journey for A Vietnamese Insurer
For this life and health insurer, underwriting turnaround time accelerated from days/weeks to an average of 15 minutes. Customers and agents were no longer left in the dark on application status. And agents no longer needed to repeatedly visit the branch to hand in documents for additional requirements.
In short, underwriting moved from a cumbersome crawl to a digital superhighway, powered by Neutrinos Low Code Development Platform.
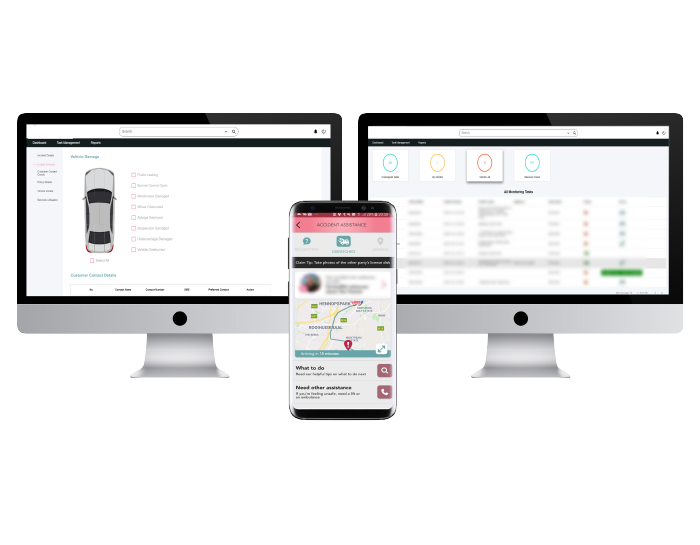
Taking the Pain Out of Claims
Transforming claims into an engine for customer loyalty
For a South African P&C Insurer, Neutrinos Low Code workflow automation became the catalyst to push the frontiers of claims excellence. Reaching out and providing incident support (ambulance, towing, …) to customers in motor accident situations, raising claims automatically through guided, empathetic interaction, and automating at every point imaginable, to make claims processing run like clockwork.
With Neutrinos Low Code Automation, claims innovation took to the skies.
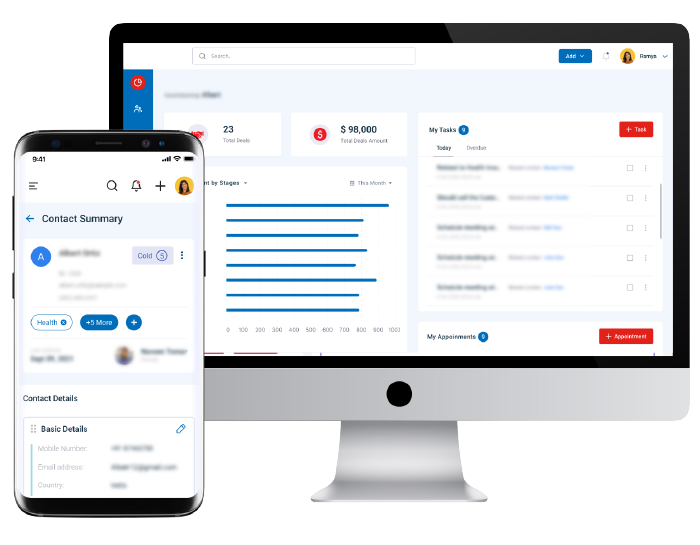
Blurring the Online-Offline Divide in Insurance Sales
Empowering agents with powerful digital engagement tools
For a major Asian insurer, good leads going stale was a constant problem. With Neutrinos low code integrations, the company reinvented agent-driven selling as a digital-first, data-driven capability. Accurate lead data, perfectly managed appointments and prospect interactions, and intelligent, insightful financial needs analysis and product recommendations: all came together in perfect synchronicity to drive a 50%+ jump in lead conversion rate.
With Neutrinos low code platform, digital-era agent productivity was unleashed, and the human touch became more powerful than ever.
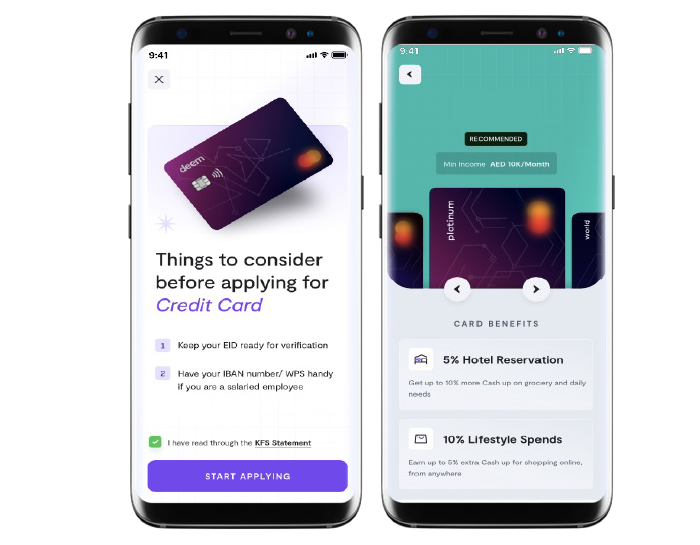
Bringing Digital Customer Engagement to Life
Web and mobile portal for customer journeys in financial services
Fully online, new account opening with turnaround time cut down from days to minutes. Online onboarding and KYC with real-time validation against government databases. Instant document verification and feedback and point of submission. And a comfortable, conversational feel at each touchpoint.
The futuristic customer engagement and servicing vision at this NBFC became a reality, with Neutrinos low code automation.
Enter the Neutriverse of imagination




And grow further with our partners
We don’t just keep great company. We also help others at it!
It’s not just our customers, but our partners too!
Our ecosystem is home to many stories of businesses reimagining their digital footprint with our fast and efficient deployment capabilities.
Discover what’s NEU at Neutrinos
